
Historically, one of the nice things about Unix and Linux is that everything is a file, and files are just sequences of characters. Of course, modern practice is that everything is not a file, and there is a proliferation of files with some imposed structure. However, if you’ve ever worked on old systems where your file access was by the block, you’ll appreciate the Unix-like files. Classic tools like awk, sed, and grep work with this idea. Files are just characters. But this sometimes has its problems. That’s the motivation behind a tool called Miller, and I think it deserves more attention because, for certain tasks, it is a lifesaver.
The Problem
Consider trying to process a comma-delimited file, known as a CSV file. There are a lot of variations to this type of file. Here’s one that defines two “columns.” I’ve deliberately used different line formats as a test, but most often, you get one format for the entire file:
Slot,String A,"Hello" "B",Howdy "C","Hello Hackaday" "D","""Madam, I'm Adam,"" he said." E 100,With some spaces! X,"With a comma, or two, even"
The first column, Slot, has items A, B, C, D, and E 100. Note that some of the items are quoted, but others are not. In any event, the column content is B not “B” because the quotes are not part of the data.
The second column, String, has a mix of quotes, no quotes, spaces, and even commas inside quotes. Suppose you wanted to process this with awk. You can do it, but it is painful. Notice the quotes are escaped using double quotes, as is the custom in CSV files. Writing a regular expression to break that up is not impossible but painful. That’s where Miller comes in. It knows about data formats like CSV, JSON, KDVP8, and a few others. It can also output in those formats and others like Markdown, for example.
Simple Example Runs
Because it knows about the format, it can process the file handily:
$ mlr –icsv cat miller.in
Slot=A,String=Hello
Slot=B,String=Howdy
Slot=C,String=Hello Hackaday
Slot=D,String=”Madam, I’m Adam,” he said.
Slot=E 100,String=With some spaces!
Slot=X,String=With a comma, or two, even
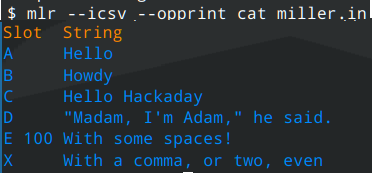 Notice there is no command called “miller.” The command name is “mlr.” This output wouldn’t be a bad format to further process with
Notice there is no command called “miller.” The command name is “mlr.” This output wouldn’t be a bad format to further process with awk, but we don’t have to. Miller can probably do everything we need. Before we look at that, though, consider what would happen if you just wanted a pretty format output:
Not too bad! Don’t forget, the tool would do the same trick with JSON and other formats, too.
So Many Options
The number of options can be daunting. There are options to pass or ignore comments, process compressed data, or customize the input or output file format a bit.
But the real power to Miller is the verbs. In the above example, the verb was cat. These are mostly named after the Linux commands they duplicate. For example, cut will remove certain fields from the data. The grep, head, and tail commands all do what you expect.
There are many new verbs, too. Count will give you a count of how much data has gone by and filter is a better version of grep. You can do database-like joins, sorting, and even statistics and generate text-based bar graphs.
The filter and put commands have an entire programming language at their disposal that has all the things you’d expect to find in a language like awk or Perl.
What’s nice is that when you want to remove a field or sort, you can refer to it by name (like “Slot”), and Miller will know what you mean. There is a way to refer to fields with numbers if you must, but that’s a rare thing in a Miller script.
For example, if you have some data with fields “stock” and “reserve” that you want to get rid of, you could write something like this:
mlr --icsv --opprint cut -f stock,reserve inventory.csv
Or, perhaps you want to select lines where stock is “N”:
mlr --icsv --opprint filter '$stock == "N"' inventory.csv
Go Read
There’s simply not enough room to cover all the features of this powerful program. I’d suggest you check out Miller in 10 Minutes which is part of the official documentation. You’ll still need to read the documentation further, but at least you’ll have a good start.
Don’t get me wrong, we still like awk. With a little work, you can make it do almost anything. But if you can do less work with Miller, why not?













0 Commentaires