Ever needed to get data from a web page? Parsing the content for data is called web scraping, and [Doug Guthrie] has a few tips for making the process of digging data out of a web page simpler and more efficient, complete with code examples in Python. He uses getting data from Yahoo Finance as an example, because it’s apparently a pretty common use case judging by how often questions about it pop up on Stack Overflow. The general concepts are pretty widely applicable, however.
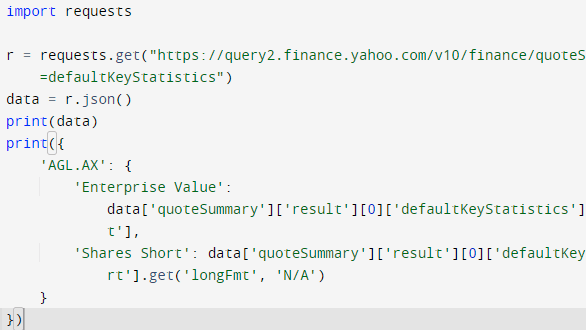
 [Doug] shows that while parsing a web page for a specific piece of data (for example, a stock price) is not difficult, there are sometimes easier and faster ways to go about it. In the case of Yahoo Finance, the web page most of us look at isn’t really the actual source of the data being displayed, it’s just a front end.
[Doug] shows that while parsing a web page for a specific piece of data (for example, a stock price) is not difficult, there are sometimes easier and faster ways to go about it. In the case of Yahoo Finance, the web page most of us look at isn’t really the actual source of the data being displayed, it’s just a front end.
One way to more efficiently scrape data is to get to the data’s source. In the case of Yahoo Finance, the data displayed on a web page comes from a JavaScript variable that is perfectly accessible to the end user, and much easier to parse and work with. Another way is to go one level lower, and retrieve JSON-formatted data from the same place that the front-end web page does; ignoring the front end altogether and essentially treating it as an unofficial API. Either way is not only easier than parsing the end result, but faster and more reliable, to boot.
How does one find these resources? [Doug] gives some great tips on how exactly to do so, including how to use a web browser’s developer tools to ferret out XHR requests. These methods won’t work for everything, but they are definitely worth looking into to see if they are an option. Another resource to keep in mind is woob (web outside of browsers), which has an impressive list of back ends available for reading and interacting with web content. So if you need data for your program, but it’s on a web page? Don’t let that stop you!













0 Commentaires